凌云的博客
行胜于言
如何搭建一个 3 个节点的 Hadoop Cluster
分类:hadoop| 发布时间:2018-05-20 18:30:00
概述
本文主要讲述了如何使用 3 台机器来创建一个最简单的 Hadoop Cluster。
假设有 3 台机器:
- node-master: 192.168.1.10
- node1: 192.168.1.11
- node2: 192.168.1.12
创建 hadoop 用户
- 创建用户
% sudo useradd --home-dir /home/hadoop -m --shell /bin/bash hadoop
% sudo passwd hadoop
- 将 hadoop 用户添加进 sudoers 在 /etc/sudoers 添加如下内容:
hadoop ALL=(ALL:ALL) ALL
切换到 hadoop 用户,以下操作均在 hadoop 用户进行操作
安装 Hadoop
参考: Hadoop 编译以及安装 一文安装 Hadoop。
修改 hosts 文件
修改 /etc/hosts 文件,添加以下 3 行(需要分别在 3 个节点进行配置):
192.168.1.10 node-master
192.168.1.11 node1
192.168.1.12 node2
配置 SSH key
- 生成 SSH key
% ssh-keygen -b 4096
- 复制 SSH key 到节点
% ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node-master
% ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node1
% ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node2
修改 Hadoop 的配置文件
以下配置文件若无特别说明均位于 $HADOOP_INSTALL_DIR/etc/hadoop 目录下。
设置 Hadoop 环境变量
- 设置 JAVA_HOME 通过 以下命令查找出 java 所在的目录:
% update-alternatives --display java
java - 手动模式
链接目前指向 /usr/lib/jvm/java-8-oracle/jre/bin/java
/usr/lib/jvm/java-8-oracle/jre/bin/java - 优先级 1081
slave java.1.gz:/usr/lib/jvm/java-8-oracle/man/man1/java.1.gz
目前“最佳”的版本为 /usr/lib/jvm/java-8-oracle/jre/bin/java。
- 设置 hadoop 日志目录 hadoop 默认的日志在 $HADOOP_INSTALL_DIR/logs 目录下,我们可以通过设置 HADOOP_LOG_DIR 环境变量进行更改
在 $HADOOP_INSTALL_DIR/etc/hadoop/hadoop-env.sh 这个文件添加以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle/jre
export HADOOP_LOG_DIR=/var/log/hadoop
创建日志目录,并且将其所有者修改为 hadoop 用户
% sudo mkdir -p /var/log/hadoop
% sudo chown hadoop:hadoop /var/log/hadoop
设置 NameNode 的地址
修改 $HADOOP_INSTALL_DIR/etc/hadoop/core-site.xml 为如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node-master:9000</value>
</property>
</configuration>
设置 HDFS 相关目录
修改 $HADOOP_INSTALL_DIR/etc/hadoop/hdfs-site.xml 为如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hdfs/dataNode</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/hadoop/hdfs/namesecondary</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
其中 dfs.replication 为 HDFS 中的数据保存多少份,由于我们这里只有两个 datanode 因此将其设置为 1。 当然也可以将其设置为 2,这样每个 datanode 都有相同的数据,这里的值不能大于 datanode 的个数。
配置 YARN
- 配置 mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
以上配置将 mapreduce 作业的调度器设置为 YARN
- 配置 yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>hadoop classpath output</value>
</property>
</configuration>
其中 yarn.application.classpath 的值需要配置为命令 hadoop classpath 得到的值。
配置 workers
需要在 workers 文件添加所有的数据节点
node1
node2
配置内存分配
对于内存不足 8G 的主机来说,内存分配比较麻烦。
如果你的 node1 和 node2 的内存大于等于 8G,则可以跳过这部分内容。 这部分内容会介绍 MapReduce 作业的内存如何分配,以及假设我们只有 2G 内存将如何进行配置使得集群可以正常运行。
内存分配属性
一个 YARN 作业是由以下两种资源构成的:
- 一个用于监控和响应集群中的应用的 Application Master(AM)
- 由 AM 创建的用于执行作业操作的 executors。对于 MapReduce 作业来说,这会是 map 或者 reduce 操作。
所有这些都运行在 workers 节点。每个 worker 节点会有一个用于创建 container 的 NodeManager 守护进程。 ResouceManager 用于调度整个 cluster 中的 container 到各个 workers 节点。
我们需要配置以下 4 中资源分配属性:
- 在单个节点中,有多少内存可以分配给 YARN containers。这个属性应该设置的比其他的属性都要高,不然会导致 container 无法创建,进而导致应用失败。当然这个值不能设置为节点的内存大小。 这个值由 yarn-site.xml 的 yarn.nodemanager.resource.memory-mb 进行配置。
- 单个 container 能使用的内存范围。内存的分配将是其最小值的整数倍。 这些值由 yarn-site.xml 的 yarn.scheduler.maximum-allocation-mb 以及 yarn.scheduler.minimum-allocation-mb 进行配置。
- ApplicationMaster 能使用多少内存,这个值应该等于 container 能使用的内存的最大值。 由 mapred-site.xml 的 yarn.app.mapreduce.am.resource.mb 属性进行配置。
- 每个 map 或者 reduce 所使用的内存大小,这个值需要比 container 的最大值要小。 由 mapred-site.xml 的 mapreduce.map.memory.mb and mapreduce.reduce.memory.mb 属性进行配置。
这些属性的关系为:
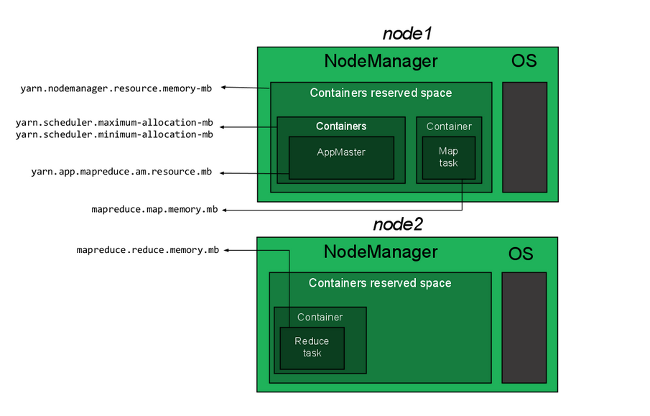
一个 2G 内存的配置例子
对于一个只有 2G 内存的节点可以配置如下:
| 属性 | 值 |
|---|---|
| yarn.nodemanager.resource.memory-mb | 1536 |
| yarn.scheduler.maximum-allocation-mb | 1536 |
| yarn.scheduler.minimum-allocation-mb | 128 |
| yarn.app.mapreduce.am.resource.mb | 512 |
| mapreduce.map.memory.mb | 256 |
| mapreduce.reduce.memory.mb | 256 |
- yarm-site.xml 在 这个配置文件添加如下属性配置:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
最后一个属性取消虚拟内存的使用限制。
- mapred-site.xml 添加如下属性配置:
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value>
</property>
复制配置文件到每个节点
假设上面的配置已经在 node-master 进行配置,现在需要将其复制到 node1 和 node2。 假设 hadoop 都安装在 /home/hadoop/hadoop-3.1.0 目录下,使用如下命令:
% cd /home/hadoop/hadoop-3.1.0/etc/hadoop
% scp -r * node1:~/hadoop-3.1.0/etc/hadoop
% scp -r * node2:~/hadoop-3.1.0/etc/hadoop
格式化 HDFS
在使用 HDFS 之前需要先将其格式化,在 node-master 节点使用如下命令进行格式化:
% hdfs namenode -format
运行与使用 HDFS
格式化后需要先运行 namenode 和 datanode 的守护进程才能操作 HDFS。
- 在 ndoe-master 使用如下命令启用:
% start-dfs.sh
- 启用后可以使用 jps 命令查看守护进程是否正确运行。
- 在 node-master 下应该有类似如下的输出
% jps
3169 Jps
2137 NameNode
2383 SecondaryNameNode
- 在 node1 和 node2 下应该有类似如下输出:
% jps
2386 Jps
1978 DataNode
- 在 node-master 使用如下命令查看 cluster 各个节点的信息
% hdfs dfsadmin -report
- 在 node-master 使用如下命令停止 HDFS
% stop-dfs.sh
启动后就可以使用 hdfs dfs 命令来操作 HDFS 了。
运行 YARN
- 启动 YARN
% start-yarn.sh
- 查看守护进程是否运行
- node-master
% jps
2641 ResourceManager
3682 Jps
2137 NameNode
2383 SecondaryNameNode
- node1 node2
% jps
2537 Jps
2105 NodeManager
1978 DataNode
- 停止 YARN
% stop-yarn.sh
可以通过以下命令查看正在运行的 YARN 节点
% yarn node -list
通过以下命令查看正在运行的 application
% yarn application -list
提交 MapReduce 作业到 YARN
我们以 Hadoop Book Example Code 的 MaxTemperature 为例,测试下搭建的cluster 能否正常运行 mapreduce 作业
- 将输入文件写入 HDFS
% cd hadoop-book
% hdfs dfs -mkdir -p .
% hdfs dfs -put input/ncdc/sample.txt
- 提交作业
% hadoop jar hadoop-examples.jar MaxTemperature sample.txt output
× 查看结果
% hdfs dfs -cat output/part-r-00000
1949 111
1950 22