凌云的博客
行胜于言
Redis 5 数据结构(二)压缩列表
分类:Redis| 发布时间:2019-04-15 21:23:00
概述
本文是 Redis 5 数据结构系列的第二篇,主要讲解压缩列表(ziplist)的结构和实现细节。
压缩列表的构成
ziplist 的源代码在 src/ziplist.h 和 src/ziplist.c 文件中。
压缩列表的各个部分

注意:所有字段如无特别说明,均以小端格式保存。
| 字段 | 类型 | 说明 |
|---|---|---|
| zlbytes | uint32_t | 用于保存压缩列表的长度(单位为字节),包括 4 字节的 zlbytes 本身。通过值可以快速调整整个压缩列表的大小,而无需遍历整个压缩列表 |
| ztail | uint32_t | 用于记录列表中最后一个节点的偏移。通过这个值可以快速的从队列末尾弹出一个节点,而无需遍历整个列表 |
| zllen | uint16_t | 记录压缩列表中节点的数量。当节点数量超过或者等于 UINT16_MAX(65535) 时,需要遍历整个列表才能知道节点的数量(一旦列表到达 UINT16_MAX,即使后面将部分节点从列表中删除,使得列表节点数小于 UINT16_MAX 这个字段依然会保持 UINT16_MAX 不变) |
| zlend | uint8_t | 是一个特殊的节点,用于表示压缩列表的末尾。它的值为 255。其他普通的节点不会以 255 开头。因此可以通过检查节点的地一个字节是否等于 255 从而知道是否已经到达列表的末尾 |
压缩列表节点的构成
注意:所有字段如无特别说明,均以小端格式保存。
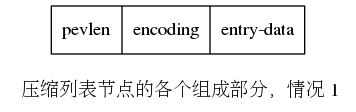
压缩列表的每个节点都以两个字段开头。
- 第一个字段是上一个节点的长度(prevlen),通过这个字段可以从后往前遍历列表。
- 第二个字段是该节点的编码方式(encoding)。指示了本节点的节点类型是字节数组类型还是整数类型。 如果是字节数组类型还包含了字节数组的长度。
下图展示了一个完整的节点的组成
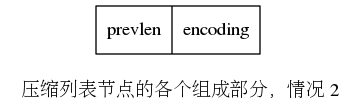
对于一些很小的数字,会在 encoding 字段包含了数字本身。 在这种情况下不需要 <entry-data> ,此时节点会如下所示
prevlen 以如下方式编码:
如果长度小于 254 字节,则 prevlen 只需要一个字节(uint8_t)来表示。 当长度大于等于 254 字节,需要 5 个字节。第一个字节为 254(FE)表示后面跟着一个 32 位的整数。
因此具体来讲,一个节点可能以如下方式编码:

如果上一个节点长度大于 253 字节时,将以如下方式编码:

根据节点保存的数据不同,encoding 字段会有不同的形式。 以下是具体的编码方式:
| 编码 | 大小 | 说明 |
|---|---|---|
| 00pppppp | 1 字节 | 保存小于等于 63 个字符的字节数组(6 比特)。"pppppp" 表示 6 比特大小的无符号整数长度 |
| 01pppppp qqqqqqqq | 2 字节 | 保存小于等于 16383 个字符的字节数组(14 比特)。重要:14 比特的数字是以大端编码保存的 |
| 10000000 qqqqqqqq rrrrrrrr ssssssss tttttttt | 5 字节 | 保存大于等于 16384,小于等于 32^2-1 个字符的字节数组(32 比特),第一个字节的低 6 位未用。重要:32 比特的数字是以大端编码保存的 |
| 11000000 | 1 字节 | 保存 2 字节有符号整数(int16_t)的编码 |
| 11010000 | 1 字节 | 保存 4 字节有符号整数(int32_t)的编码 |
| 11100000 | 1 字节 | 保存 8 字节有符号整数(int64_t)的编码 |
| 11110000 | 1 字节 | 保存 3 字节有符号整数(24 位)的编码 |
| 11111110 | 1 字节 | 保存 1 字节有符号整数(int8_t)的编码 |
| 1111xxxx | 1 字节 | (xxxx 取值为 0001 到 1101)保存 0 到 12 的整数编码,xxxx 为 0001 时表示保存的是 0,依此类推 |
| 11111111 | 1 字节 | 表示压缩列表的末尾节点 |
当节点保存的是整数时,保存的整数将以小段格式保存。
压缩列表的例子
下面是一个包含了数字 "2" 和 "5" 的压缩列表的例子。 这个列表由 15 个字节组成:
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
| | | | | |
zlbytes zltail entries "2" "5" end
前面 4 个字节表示的是数字 15,也就是组成压缩列表的总字节数。 将下来的 4 个字节表示列表中最后一个节点的偏移,在这里是 12,指向 "5" 这个节点。 再接下来的 2 字节 表示压缩列表中的节点个数,在这里是 2。 最后 "00 f3" 表示的是列表的第一个节点,代表数组 2。这个节点的第一个字节表示上一个节点的长度,由于这是列表的第一各节点,因此该值为 0, 第二个字节为编码方式,这里用到了上述的 |1111xxxx| 编码,数字 2 直接保存在了 xxxx 中,无 entry-data 部分,xxxx 为 3 表示实际数字为 2。下一个节点为 [02 f6],02 表示上一个节点的长度为 2,f6 一样使用到了 |1111xxxx| 编码,xxxx 部分为 6, 6-1=5,表示保存的数字为 5,然后最后的一个字节 'ff' 是一个特殊节点,表示列表的末尾。
当我们将内容为 "Hello World" 的节点添加到上述的压缩列表的末尾时,新增的节点的内容为:
[02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
此节点会跟在上述的节点 "5" 后面,第一个字节 02 表示上一个节点的长度,0b 是编码方式,对应上表的 |00pppppp| 编码格式, pppppp 部分为 'b' 也就是 11,这正好等于 "Hello World" 的长度,将下来的 48 到 64 就是 "Hello World" 的 ASCII 码。
压缩列表 API
unsigned char *ziplistNew(void);
创建一个空的压缩列表
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second);
合并 'first' 和 'second' 两个压缩列表,将 'second' 追加到 'first' 后面。
注意:函数内部会将 'first' 或者 'second' reallocated 为一个能包含两个压缩列表的大的压缩列表。 另一个参数会被设置为 NULL。
如果无法进行合并则会返回 NULL 表示合并失败。 否则返回合并后的压缩列表(为 'first' 或者 'second' 扩大后的版本,另一个列表的空间会被释放,输入的参数会被设置为 NULL)。
#define ZIPLIST_HEAD 0
#define ZIPLIST_TAIL 1
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where);
将数据压入列表,如果 where 为 ZIPLIST_HEAD 则压入列表的头,否则压入列表的尾。
unsigned char *ziplistIndex(unsigned char *zl, int index);
返回列表的第 index 个节点,当 index 为负数时,从后往前遍历。 当列表中不存在索引为 index 的节点时,返回 NULL。
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p);
返回列表 zl 的节点 p 的下一个节点,当 p 是最后一个节点时,返回 NULL。
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p);
返回列表 zl 的节点 p 的上一个节点,当 p 是第一个节点时,返回 NULL。
unsigned int ziplistGet(unsigned char *p, unsigned char **sstr, unsigned int *slen, long long *sval);
返回节点 'p' 的内容,根据编码不同数据将保存在 'sval' 或者 'sstr'。 若数据为为整数,则 'sstr' 设置为 NULL,数据保存在 sval,若数据为字节数组,则数据保存在 'sstr' 。 当 'p' 指向列表的末尾('FF')时,返回 0,否则返回 1。
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen);
将数据插入 'p' 节点所在位置,'p' 以及之后的节点依次往后移。
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p);
删除 'p' 指向的节点,并原地更新 'p',这样我们可以在对列表迭代过程中删除节点。
unsigned char *ziplistDeleteRange(unsigned char *zl, int index, unsigned int num);
删除范围内的节点。
unsigned int ziplistCompare(unsigned char *p, unsigned char *s, unsigned int slen);
比较 'p' 的内容和 's' 是否相等,若相等返回 1,否则返回 0。
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip);
查找 'p' 指向的节点 'skip' 个节点后的内容与 'vstr' 相等的节点。 若没找到则返回 NULL。
unsigned int ziplistLen(unsigned char *zl);
返回压缩列表的节点个数
size_t ziplistBlobLen(unsigned char *zl);
返回压缩列表所占用的字节数
void ziplistRepr(unsigned char *zl);
打印压缩列表的详细信息
连锁更新
从 压缩列表节点的构成 我们知道,节点的 prevlen 字段根据上一个节点的长度有可能是 1 个字节或者 5 个字节。 现在问题来了,当我们向列表中间插入一个节点(删除,合并操作类似,这里以插入为例子)时,下一个节点的 prevlen 本身的长度可能改变,而这个改变有可能一直往后传递,从而导致连锁更新现象。
比如有如下压缩列表:

假设 bigentry1很大,而 e2,e3 ... eN 节点长度为 255 字节(超过 254 字节),当我们插到一个小节点到 bigentry1 和 e2 之间时。
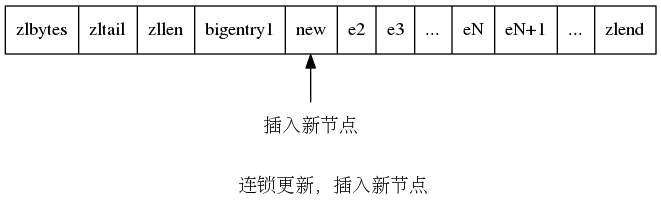
此时,由于 new 节点很小,e2 的 prevlen 由原先的 5 字节缩减为 1 字节,同时 e2 自身长度由 255 减为 251,从而引发 e3 的缩减,从而引发连锁更新,一直传递到 eN。
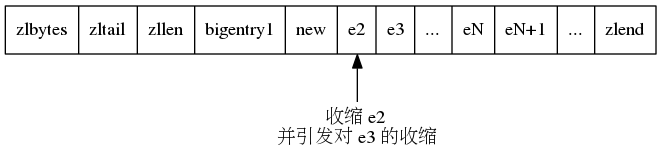
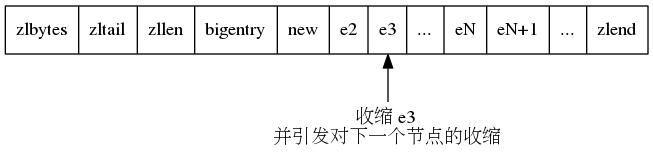

ziplist 的连锁更新操作由函数
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p);
进行处理,有兴趣的话可以到 ziplist.c 查看具体实现。
总结
- 压缩列表是设计来减少内存占用的顺序型数据结构
- 压缩列表的节点有多种的编码方式,而这有效减少了节点的内存占用量
- 压缩列表在增加,删除节点以及合并时有可能出现连锁更新,这相当耗费资源,不过正常情况下,发生的概率不高
- 压缩列表在节点数到达 UINT16_MAX 后,需要遍历列表才能得知列表有多少个节点,当到达此值后,即使后续通过删除节点使得节点个数小于 UINT16_MAX 依然需要遍历列表才能得知列表节点的个数