凌云的博客
行胜于言
LeetCode 算法题 30. 串联所有单词的子串
分类:algorithm| 发布时间:2016-08-07 21:48:00
题目
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]
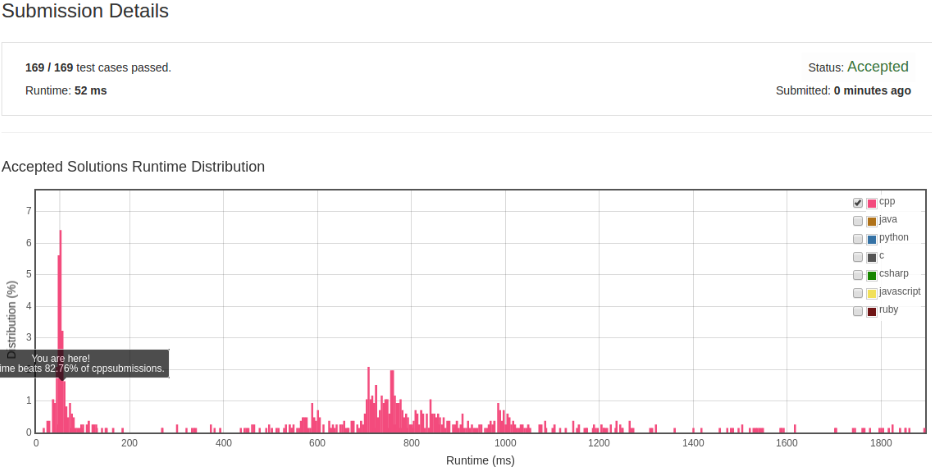
解法 1
这种解法的基本思路是将给出的 words 中每个单词出现的次数放入一个 map 中。 然后取出给定的字符串的 num * len 个字符,分为 num 个单词, 将其出现的次数放入另一个 map 中,对比这两个 map 是否相同。
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> indexes;
if (s.empty() || words.empty()) {
return indexes;
}
unordered_map<string, int> counts;
for (const string &word: words) counts[word]++;
int n = s.length(), num = words.size(), len = words[0].length();
for (int i = 0; i < n - num * len + 1; i++) {
unordered_map<string, int> seen;
int j = 0;
for (; j < num; j++) {
string word = s.substr(i + j * len, len);
if (counts.find(word) != counts.end()) {
seen[word]++;
if (seen[word] > counts[word])
break;
} else {
break;
}
}
if (j == num) indexes.push_back(i);
}
return indexes;
}
};
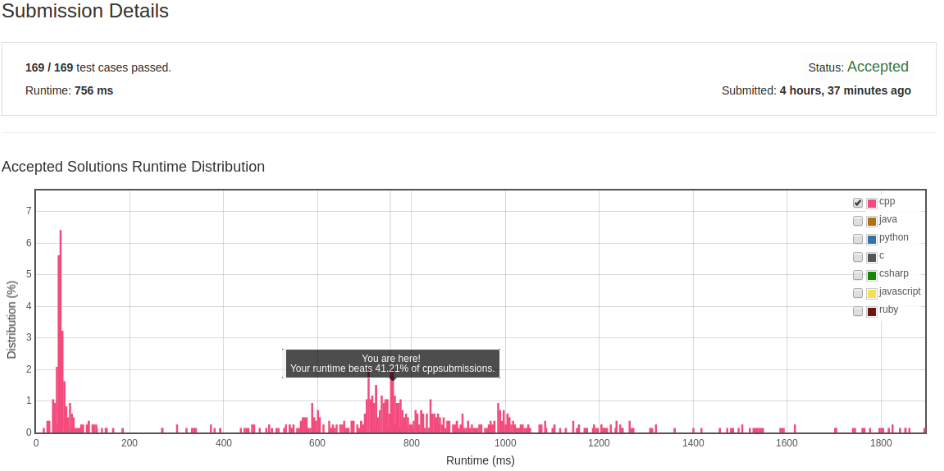
解法 2
这个算法可以看成是上一个算法经过优化得到的。 首先,外层循环 i 从 0 到 wl(wl 为一个单词的长度)。 相应地,内层循环以 wl 为单位处理整个字符串。
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> ans;
int n = s.size(), cnt = words.size();
if (n <= 0 || cnt <= 0) return ans;
// init word occurence
unordered_map<string, int> dict;
for (int i = 0; i < cnt; ++i) dict[words[i]]++;
// travel all sub string combinations
int wl = words[0].size();
for (int i = 0; i < wl; ++i) {
int left = i, count = 0;
unordered_map<string, int> tdict;
for (int j = i; j <= n - wl; j += wl) {
string str = s.substr(j, wl);
// a valid word, accumulate results
if (dict.count(str)) {
tdict[str]++;
if (tdict[str] <= dict[str]) {
count++;
} else {
// a more word, advance the window left side possiablly
while (tdict[str] > dict[str]) {
string str1 = s.substr(left, wl);
tdict[str1]--;
if (tdict[str1] < dict[str1]) count--;
left += wl;
}
}
// come to a result
if (count == cnt) {
ans.push_back(left);
// advance one word
tdict[s.substr(left, wl)]--;
count--;
left += wl;
}
} else {
// not a valid word, reset all vars
tdict.clear();
count = 0;
left = j + wl;
}
}
}
return ans;
}
};