凌云的博客
行胜于言
C++ string 实现剖析
分类:c++| 发布时间:2019-03-18 14:46:00
概述
在 Effective STL 的 “第 15 条:注意 string 实现的多样性“ 一节中提到了 string 的几种可能的实现方法, 于是查看了 GCC 关于 string 部分的源码,发现:
在 GCC 4.x,string 的默认实现使用 COW 技术,而 GCC 5.x 版本的默认实现已经不是 COW,而是通过在 string 内部通过一个 16 个字节大小的栈 buffer 优化了小字符串的创建(Small string optimization)
测试
在对代码进行剖析之前,我们可以先写一个简单的测试程序,通过 string 表现出来的行为,我们可以猜测到 string 的内部是怎么实现的。 测试代码如下:
#include <iostream>
#include <string>
#include <inttypes.h>
using namespace std;
int main(int argc, char *argv[])
{
string s("hello world");
string s2(s);
cout << "s: " << s << std::hex << " &s: 0x" << (uint64_t)&s << " sizeof(s): 0x"
<< sizeof(s) << " addr: 0x" << (uint64_t) s.c_str() << endl;
cout << "s: " << s << " addr: 0x" << (uint64_t) s.c_str() << endl;
cout << "s2: " << s2 << " addr: 0x" << (uint64_t) s2.c_str() << endl;
if (s.c_str() == s2.c_str()) {
cout << "the string is using COW tech" << endl;
} else {
cout << "the string is not using COW tech" << endl;
}
char *p = const_cast<char*>(s.c_str());
*p = 'w';
cout << "s: " << s << " addr: 0x" << (uint64_t) s.c_str() << endl;
cout << "s2: " << s2 << " addr: 0x" << (uint64_t) s2.c_str() << endl;
string substr = s.substr(6);
cout << "substr: " << substr << " addr: 0x" << (uint64_t) substr.c_str() << endl;
return 0;
}
// vim: set et ts=4 sts=4 sw=4:
通过 GCC 4.6 编译上述代码,得到的运行结果为:
s: hello world &s: 0x7fff4e13a3f0 sizeof(s): 0x8 addr: 0x1f52028
s: hello world addr: 0x1f52028
s2: hello world addr: 0x1f52028
the string is using COW tech
s: wello world addr: 0x1f52028
s2: wello world addr: 0x1f52028
substr: world addr: 0x1f52058
从运行结果可以知道
- GCC 4.6 的 string 用了 COW 技术来实现
- substr 方法返回的 string 会另外创建 buffer,而不是共用 buffer
- 另外由于 sizeof(string) 大小为 8,刚好等于 64 位系统下一个指针的大小,因此里面的实现很可能就是 Effective STL 里面谈到的方法 C 实现的
通过 GCC 5.4 编译上述代码,得到的运行结果为:
s: hello world &s: 0x7fffdafba5b0 sizeof(s): 0x20 addr: 0x7fffdafba5c0
s: hello world addr: 0x7fffdafba5c0
s2: hello world addr: 0x7fffdafba5e0
the string is not using COW tech
s: wello world addr: 0x7fffdafba5c0
s2: hello world addr: 0x7fffdafba5e0
substr: world addr: 0x7fffdafba600
- GCC 5.4 的 string 没有使用 COW 技术来实现
- substr 方法返回的 string 会另外创建 buffer,而不是共用 buffer
- 由于 string 本身的地址跟 c_str 返回的地址相差比 sizeof(string) 要小,估计内部的 buffer 使用的是栈上的空间而不是堆上的空间
源码剖析
SSO 版本
class string_sso
{
public:
string_sso(): data_(_M_local_buf) {
set_length(0);
}
string_sso(const string_sso& str): data_(_M_local_buf) {
construct(str.data_, str.data_ + str.len_);
}
string_sso(const char* s, size_t n = -1): data_(_M_local_buf) {
if (n == -1)
n = strlen(s);
construct(s, s + n);
}
~string_sso() {
dispose();
}
const char* c_str() const {
return data_;
}
const char& operator[](size_t i) const {
return data_[i];
}
char& operator[](size_t i) {
return data_[i];
}
private:
void dispose() {
if (data_ != _M_local_buf) {
delete [] data_;
}
}
void construct(const char *beg, const char *end) {
size_t capacity = _S_local_capacity;
if ((end - beg) > _S_local_capacity) {
dispose();
capacity = (end - beg) + 1;
data_ = new char[capacity]();
}
int len = 0;
while (beg != end) {
data_[len++] = *beg++;
}
set_length(len);
}
void set_length(size_t n) {
len_ = n;
data_[n] = '\0';
}
mutable char* data_;
size_t len_;
enum { _S_local_capacity = 15 / sizeof(char) };
union {
char _M_local_buf[_S_local_capacity + 1];
size_t _M_allocated_capacity;
};
};
在这里,我删掉所有我关心的细节之外的东西,可以看出 SSO 版本的基本思想非常简单,就是通过将小字符串保存在栈上, 从而优化 string 对于小字符串的性能。
COW 版本
#include <cstring>
using namespace std;
class string_cow
{
public:
string_cow(): data_(_S_empty_rep().refdata()) {
}
string_cow(const string_cow& str): data_(str.rep()->grab()) {
}
string_cow(const char* s): data_(_S_construct(s, s + strlen(s))) {
}
string_cow(const char* s, size_t n): data_(_S_construct(s, s + n)) {
}
~string_cow() {
rep()->dispose();
}
const char* c_str() const {
return data_;
}
size_t size() const {
return rep()->_M_length;
}
const char& operator[](size_t pos) const {
return data_[pos];
}
char& operator[](size_t pos) {
leak();
return data_[pos];
}
private:
char* _S_construct(const char* beg, const char *end) {
if (beg == end)
return _S_empty_rep().refdata();
size_t n = end - beg;
_Rep* r = _Rep::_S_create(n);
memcpy(r->refdata(), beg, n);
r->set_length_and_sharable(n);
return r->refdata();
}
void leak() {
if (!rep()->is_leaked()) {
if (rep() == &_S_empty_rep()) {
return ;
}
if (rep()->is_shared()) {
_Rep* r = _Rep::_S_create(this->size());
memcpy(r->refdata(), data_, this->size());
}
rep()->set_leaked();
}
}
struct _Rep_base {
size_t _M_length;
size_t _M_capacity;
int _M_refcount;
};
struct _Rep: _Rep_base {
// The following storage is init'd to 0 by the linker, resulting
// (carefully) in an empty string with one reference.
static size_t _S_empty_rep_storage[];
static _Rep& _S_empty_rep() {
// NB: Mild hack to avoid strict-aliasing warnings. Note that
// _S_empty_rep_storage is never modified and the punning should
// be reasonably safe in this case.
void* p = reinterpret_cast<void*>(&_S_empty_rep_storage);
return *reinterpret_cast<_Rep*>(p);
}
bool is_leaked() const {
return this->_M_refcount < 0;
}
bool is_shared() const {
return this->_M_refcount > 0;
}
void set_leaked() {
this->_M_refcount = -1;
}
void set_sharable() {
this->_M_refcount = 0;
}
void set_length_and_sharable(size_t n) {
if (this != &_S_empty_rep() ) {
this->set_sharable(); // One reference.
this->_M_length = n;
this->refdata()[n] = '\0';
}
}
char* refdata() {
return reinterpret_cast<char*>(this + 1);
}
char* grab() {
return !is_leaked()
? refcopy() : clone();
}
static _Rep* _S_create(size_t n) {
size_t size = n + sizeof(_Rep) + 1;
void* place = new char[size]();
_Rep *p = new (place) _Rep;
p->_M_capacity = n;
return p;
}
void dispose() {
if (this != &_S_empty_rep()) {
if (_M_refcount-- <= 0) {
delete [] reinterpret_cast<char*>(this);
}
}
}
char* refcopy() {
this->_M_refcount++;
return refdata();
}
char* clone() {
_Rep *r = _S_create(this->_M_capacity);
if (this->_M_length)
memcpy(r->refdata(), refdata(), this->_M_length);
r->set_length_and_sharable(this->_M_length);
return r->refdata();
}
};
static _Rep& _S_empty_rep() {
return _Rep::_S_empty_rep();
}
_Rep* rep() const {
return &((reinterpret_cast<_Rep*> (data_))[-1]);
}
private:
char *data_;
};
size_t string_cow::_Rep::_S_empty_rep_storage[
(sizeof(_Rep_base) + sizeof(char) + sizeof(size_t) - 1) /
sizeof(size_t)];
// vim: set et ts=4 sts=4 sw=4:
为了突出 COW 技术,我删掉所有无关的内容。可以看出整个 string_cow 只有一个 data_ 的成员变量, 因此 sizeof(string_cow) 的大小正好就是一个指针的大小,有关引用计数,字符串大小, 容量等信息都保存在通过 new 申请的内存里,其内存结构为:
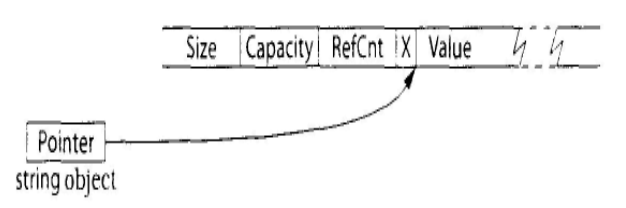
需要注意这个版本的一些优化手段:
- 空字符串,使用了静态的内存空间,因此创建一个空的字符串并不会占用堆空间
- 在执行如 string_cow s2(s1) 只会增加引用计数(s2 = s1 也类似,只是这里没实现)
- 若执行了非 const 的 operator[] string_cow 会将其管理的内存设置为非共享模式
参考
- Effective STL:第 15 条:注意 string 实现的多样性
- GCC 5 Release Series Changes, New Features, and Fixes
- New std::string implementation