凌云的博客
行胜于言
rsync 算法 [译]
分类:rsync| 发布时间:2020-02-20 15:19:00
本文译自 The rsync algorithm
摘要
该报告提出了一种算法,用于将一台计算机上的文件同步到另一台计算机。 我们假设两台机器通过低带宽高延迟双向通信链路连接。 该算法识别源文件中与目标文件中某些部分相同的部分,并且仅发送无法以这种方式匹配的部分。 该算法可以有效地计算出差异,而无需将两个文件都放在同一台计算机上。 当文件相似时,该算法效果最佳,但当文件完全不同时,该算法也将正确有效地发挥作用。
问题
假设您有两个文件 A 和 B,并且希望将 B 更新为与A相同。 最明显的方法是将 A 复制到 B。
现在,假设这两个文件位于通过慢速通信链接(例如拨号 IP 链接)连接的计算机上。 如果 A 是大文件,则将 A 复制到 B 会很慢。 为了使复制变快,您可以在发送前压缩 A,但这通常只会获得 2 到 4 倍的提升。
现在假设 A 和 B 非常相似,也许都源自同一原始文件。 为了真正加快速度,您需要利用这种相似性。 一种常见的方法是仅通过链接发送 A 和 B 之间的差异,然后使用此差异列表来重建文件。
问题在于,创建两个文件之间的差异集的常规方法依赖于两个文件都能够读取。 因此,它们要求链接的一端能够先访问这两个文件。 如果它们在同一台计算机上都不同时可用,则无法使用这些算法(一旦将文件复制过来,就不需要这些差异了)。 这是 rsync 解决的问题。
rsync 算法可以有效地计算源文件的哪些部分与现有目标文件的某些部分匹配。 这些部分不需要通过链接发送。 只需要对目标文件的哪些部分进行引用。 仅源文件中无法通过这种方式匹配的部分需要逐字发送。 然后,receiver 可以使用对现有目标文件各部分的引用和逐字记录材料来构造源文件的副本。
通常,可以使用常见的压缩算法中的任意一种来压缩发送到 receiver 的数据,以进一步提高速度。
rsync 算法
假设我们有两台通用计算机 α 和 β。 计算机 α 有权访问文件A,计算机 β 有权访问文件B,其中 A 和 B 是 '相似的'。 α 和 β 之间的通讯链接很慢。
rsync 算法包含以下步骤:
- β 将文件 B 拆分为一系列大小为 S 个字节的非重叠的固定大小的块。 最后一块可能小于 S 个字节(我们发现,在大多数情况下,S 的值介于 500和 1000 之间是非常好的)。
- β 为每个这些块计算两个校验和:弱的滚动的 32位校验和(如下所述)和强的 128 位 MD4 校验和。
- β 将这些校验和发送到 α。
- α 搜索 A 来查找所有其弱校验和以及强校验和都与 B 中的某一个块相同的长度为 S 字节的块(在任何偏移量处,不仅是 S 的倍数)。 通过下面介绍的 “滚动校验和” 的特殊属性可以非常快速地完成一次操作。
- α 向 β 发送一系列指令以构造 A 的副本。 每条指令要么是对 B 块的引用,要么是文字数据(literal data)。 仅会发送文件 A 中与 B 的任何块都不匹配的文字数据。
最终结果是 β 获得了 A 的副本,但是只通过链接发送了 A 的部分数据,这部分数据无法在 B 中找到(以及用于校验和和块索引的少量数据)。 该算法还仅需要一次往返,从而最大程度地减少了链路延迟的影响。
该算法最重要的细节是滚动校验和以及关联的多种替代搜索机制,该机制使所有偏移校验和搜索都可以非常快速地进行。 这些将在下面更详细地讨论。
滚动校验和
rsync 算法中使用的弱滚动校验和必须具有以下特性:给定缓冲区 X1 .. Xn 的校验和以及字节 X1 和 Xn 的值,计算缓冲区X2 .. Xn + 1 的校验和代价非常低。
我们在实现中使用的弱校验和算法是受 Mark Adler 的 adler-32 校验和启发的。我们的校验和定义为:
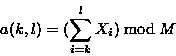
s(k,l) = a(k,l) + 216 b(k,l)
其中 s(k,l)是字节 Xk ... Xl 的滚动校验和。 为了简化和提高速度,我们使用 M = 216。
此校验和的重要属性是可以使用循环关系非常有效地计算后续值
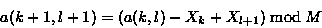
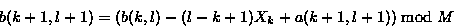
因此,可以以 '滚动' 方式为文件中所有可能的偏移量计算长度为 S 的块的校验和,而每个点的计算量很少。
尽管它很简单,但此校验和足以作为对两个文件块是否匹配的第一级检查。 在实践中我们发现,当块不相等时,此校验和匹配的概率非常低。 这很重要,因为必须为弱校验和匹配的每个块计算出昂贵得多的强校验和。
校验和搜索
一旦 α 接收到 B 块的校验和的列表,它必须在 A 处搜索与 B 块的校验和匹配的任何偏移量的任何块。 基本策略是依次从 A 的每个字节开始计算长度为 S 的块的 32 位滚动校验和,并为每个校验和在列表中搜索匹配项。 为此,我们的实现使用简单的 3 级搜索方案。
第一级使用 32 位滚动校验和的 16 位哈希和 216 个条目哈希表。 所有的校验和(即来自B块的校验和)会根据 32 位滚动校验和的 16 位哈希值进行排序。 哈希表中的每个条目都指向该哈希值的列表的第一个元素,或者如果列表中的任何元素都不具有该哈希值,则包含一个空值。
在文件中的每个偏移处,都会计算 32 位滚动校验和及其 16 位哈希。 如果该哈希值的哈希表条目不是空值,则调用第二级检查。
第二级检查涉及从哈希表条目所指向的条目开始扫描已排序的校验和列表,查找其 32 位滚动校验和与当前值匹配的条目。 当遇到一个 16 位哈希值不同的条目时,扫描将终止。 如果此搜索找到匹配项,则调用第三级检查。
第三级检查包含计算文件中当前偏移量的强校验和,并将其与当前列表条目中的强校验和进行比较。 如果两个强校验和匹配,则假定我们找到了一个与 B 块匹配的 A 块。 实际上,这些块可能是有差异的,但是这种可能性非常小,在实践中,这是一个合理的假设。
找到匹配项后,α 会向 β 发送 A 中当前文件偏移量和上一个匹配项的结尾之间的数据,然后发送匹配的 B 中块的索引。 找到匹配项后立即发送此数据,这使得我们可以将通信时间与接下来的计算时间重叠。
如果在文件中的给定偏移量处未找到匹配项,则计算出下一个偏移量的滚动校验和,然后继续搜索。 如果找到匹配项,则在匹配块的末尾重新开始搜索。 对于两个文件几乎相同的常见情况,此策略节省了大量计算。 另外,对于 A 的一部分按顺序匹配 B 的一系列块的常见情况,在运行时将块索引编码将是一件简单的事情。
Pipelining
以上各节描述了在远程系统上构造一个文件副本的过程。 如果要复制几个文件,则可以通过将整个过程流水线化来获得相当大的延迟优势。
这涉及 β 启动的两个独立的进程。 其中一个进程生成并发送校验和到 α,而另一个进程接收来自 α 的差异信息并重建文件。
如果对通信链路进行缓冲,则这两个过程可以独立进行,并且在大多数情况下,应始终在两个方向上充分利用链路。
结果
为了测试算法,使用两个版本的Linux 内核源文件创建了 tar 文件。 两个内核版本是 1.99.10 和 2.0.0。 这些 tar 文件的大小约为 24MB,并分隔为 5 个已发布的补丁。
在 1.99.10 版本中的 2441个文件,在 2.0.0 版本中更改了其中 291 个文件,删除了 19 个文件,并新增了 25 个文件。
使用标准GNU 'diff' 实用程序对两个 tar文件进行 比较 后,产生了超过 3.2 万行的输出,总计 2.1 MB。
下表显示了具有不同块大小的两个文件之间的rsync结果。(本节中的所有测试都是使用 rsync 0.5 版本进行的)
| block size | matches | tag hits | false alarms | data | written | read |
|---|---|---|---|---|---|---|
| 300 | 64247 | 3817434 | 948 | 5312200 | 5629158 | 1632284 |
| 500 | 46989 | 620013 | 64 | 1091900 | 1283906 | 979384 |
| 700 | 33255 | 571970 | 22 | 1307800 | 1444346 | 699564 |
| 900 | 25686 | 525058 | 24 | 1469500 | 1575438 | 544124 |
| 1100 | 20848 | 496844 | 21 | 1654500 | 1740838 | 445204 |
在每种情况下,占用的 CPU 时间都少于在两个文件上运行 diff 所花费的时间。(在运行 SunOS 的 50 MHz SPARC 10 上,使用 rsh over loopback 进行通信,每次运行的时钟时间约为2分钟。GNU diff花费了大约4分钟。)
表中各列的含义如下:
- block size 校验和块的大小(以字节为单位)。
- matches 在 A 中发现 B 块的次数。
- tag hits 滚动校验和的 16 位哈希与来自 B 的校验和之一的哈希匹配的次数。
- false alarms 32 位滚动校验和匹配但强校验和不匹配的次数。
- data 逐字传输的文件数据量(以字节为单位)。
- written α 写入的字节总数,包括协议开销。这几乎是所有文件数据。
- read α 读取的字节总数,包括协议开销。这几乎是所有校验和信息。
结果表明,对于大于300字节的块大小,仅传输文件的一小部分(大约5%)。 如果使用更新远程文件的 diff/patch 方法,则传输的数量也大大小于 diff 文件的大小。
尽管每种情况下校验和本身比传输的数据的大小要小得多,但是校验和本身还是占用了相当的空间。 每对校验和需要消耗 20 个字节:滚动校验和为 4 个字节,而 128 位 MD4 校验和为 16 个字节。
false alarms 的数量少于真实匹配数量的 1/1000,这表明 32 位滚动校验和非常适合筛选错误匹配。
tag hits 次数表明第二级的校验和搜索算法大约每 50 个字符被调用一次。 这相当高,因为文件中的块总数是 tag 哈希表大小的很大一部分。 对于较小的文件,我们期望 tag hits 与匹配数更加接近。 对于非常大的文件,我们可能需要增加哈希表的大小。
下表显示了一组较小文件的结果。 在这种情况下,文件没有打包到 tar 文件中。 而是通过启用递归选项来使 rsync 遍历目录树。 这次测试使用了另一个称为 Samba 的软件包。 使用的文件来自另一个名为 Samba 软件包的两个源版本。 总的源码大小为 1.7 MB ,两个发布版之间有 4155 行不同,差别大小总共是 120 kB。
| block size | matches | tag hits | false alarms | data | written | read |
|---|---|---|---|---|---|---|
| 300 | 3727 | 3899 | 0 | 129775 | 153999 | 83948 |
| 500 | 2158 | 2325 | 0 | 171574 | 189330 | 50908 |
| 700 | 1517 | 1649 | 0 | 195024 | 210144 | 36828 |
| 900 | 1156 | 1281 | 0 | 222847 | 236471 | 29048 |
| 1100 | 921 | 1049 | 0 | 250073 | 262725 | 23988 |
可用性
已编写了 rsync 的实现,该实现提供了类似于常见 UNIX 命令 rcp 的便捷接口,可以从 ftp://rsync.samba.org/pub/rsync 下载。