凌云的博客
行胜于言
Linux 内核概述(总)
分类:linux| 发布时间:2025-01-26 18:12:00
Unix内核提供了一个执行环境,应用程序可以在其中运行。 因此,内核必须实现一组服务和相应的接口。应用程序通过这些接口进行交互,通常不会直接与硬件资源交互。
进程/内核模型
CPU可以在用户模式(User Mode)或内核模式(Kernel Mode)下运行。 实际上,一些 CPU 可能有超过两种执行状态。 例如,80x86 微处理器有四种不同的执行状态。但所有标准的 Unix 内核只使用内核模式和用户模式。
当程序在用户模式下执行时,它不能直接访问内核数据结构或内核程序。 然而,当应用程序在内核模式下执行时,这些限制就不再适用。 每种CPU型号都提供特殊指令,用于在用户模式和内核模式之间切换。 程序通常在用户模式下执行,只有在请求内核提供的服务时,才会切换到内核模式。 当内核满足了程序的请求后,它会将程序切换回用户模式。
进程是动态实体,通常在系统中有一个有限的生命周期。 创建、消除和同步现有进程的任务由内核中的一组例程处理。
内核本身不是一个进程,而是一个进程管理器。 进程/内核模型假定,所有需要内核服务的进程使用一种叫做系统调用(system calls)的特定编程结构。 每个系统调用都会设置一组参数,用以标识进程请求,然后执行硬件相关的 CPU 指令,将程序从用户模式切换到内核模式。
除了用户进程,Unix系统还包括一些特权进程,称为内核线程,具有以下特点:
- 它们在内核模式下运行,并处于内核地址空间中。
- 它们不与用户交互,因此不需要终端设备。
- 它们通常在系统启动时创建,并在系统关闭之前一直存在。
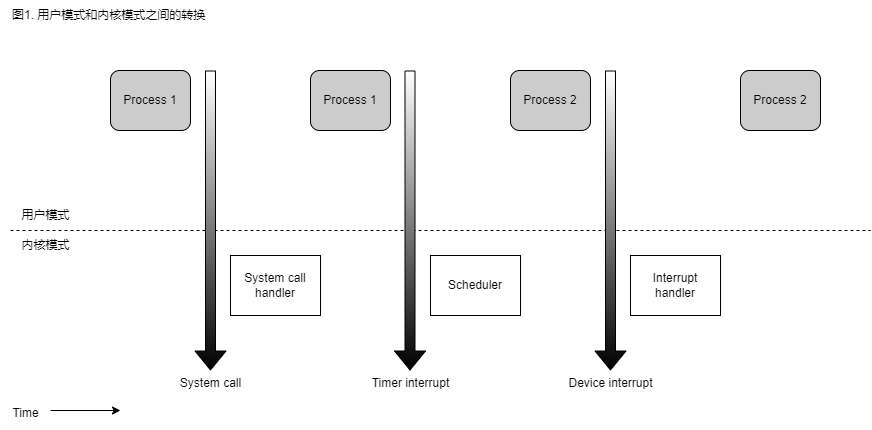
在单处理器系统上,任何时候只有一个进程在运行,它可以在用户模式或内核模式下运行。 如果它在内核模式下运行,处理器正在执行某个内核例程。 图 1 展示了用户模式和内核模式之间切换的示例。 进程 1 在用户模式下发出系统调用,之后进程切换到内核模式,系统调用被服务。 进程 1 随后在用户模式下继续执行,直到发生定时器中断,调度程序在内核模式下被激活。 进程切换发生,进程 2 开始在用户模式下执行,直到硬件设备触发中断。 由于中断,进程 2 切换到内核模式并处理该中断。
Unix内核的功能不仅仅是处理系统调用;实际上,内核例程可以通过多种方式被激活:
- 一个进程调用系统调用。
- 执行进程的 CPU 发出异常信号,这是一种异常情况,例如无效指令。内核代表引发异常的进程处理该异常。
- 外围设备向 CPU 发出中断信号,以通知它发生了某些事件,如请求注意、状态变化或I/O操作完成。每个中断信号由一个称为中断处理程序的内核程序处理。由于外围设备与 CPU 异步操作,中断在不可预测的时刻发生。
- 一个内核线程被执行。由于它在内核模式下运行,相关程序必须视为内核的一部分。
进程实现
为了让内核管理进程,每个进程都由一个进程描述符表示,进程描述符包含有关进程当前状态的信息。
当内核停止执行一个进程时,它会将多个处理器寄存器的当前内容保存在进程描述符中。这些寄存器包括:
- 程序计数器(PC)和栈指针(SP)寄存器
- 通用寄存器
- 浮点寄存器
- 处理器控制寄存器(处理器状态字),包含关于 CPU 状态的信息
- 内存管理寄存器,用于跟踪进程访问的RAM
当内核决定恢复执行一个进程时,它会使用适当的进程描述符字段来加载 CPU 寄存器。 由于程序计数器的存储值指向最后执行指令之后的指令,进程会从停止的位置继续执行。
当进程没有在 CPU 上执行时,它在等待某个事件。 Unix内核区分了许多等待状态,这些状态通常通过进程描述符的队列来实现;每个(可能为空的)队列对应于一组等待特定事件的进程。
可重入内核
所有 Unix 内核都是可重入的。 这意味着多个进程可以同时在内核模式下执行。 当然,在单处理器系统上,只有一个进程可以进行处理,但许多进程可以在内核模式下被阻塞,等待 CPU 或某些 I/O 操作的完成。 例如,在代表某个进程发出对磁盘的读取请求后,内核会让磁盘控制器处理该请求,并恢复执行其他进程。 中断会在设备完成读取时通知内核,这样前一个进程就可以恢复执行。
提供可重入性的一种方式是编写函数,使其只修改局部变量而不改变全局数据结构。 这样的函数称为可重入函数。然而,可重入内核不仅限于这种可重入函数(尽管某些实时内核是通过这种方式实现的)。 相反,内核可以包含不可重入的函数,并使用锁机制确保一次只有一个进程可以执行不可重入函数。
如果发生硬件中断,可重入内核能够暂停当前正在运行的进程,即使该进程在内核模式下。 这一能力非常重要,因为它提高了发出中断的设备控制器的吞吐量。 一旦设备发出中断,它会等待直到 CPU 确认。 如果内核能够快速响应,设备控制器就能够在 CPU 处理中断的同时执行其他任务。
现在让我们来看一下内核的可重入性及其对内核组织结构的影响。 内核控制路径指的是内核为处理系统调用、异常或中断而执行的指令序列。
在最简单的情况下,CPU会顺序地从第一条指令执行到最后一条指令来执行内核控制路径。然而,当以下事件发生时,CPU会交错执行内核控制路径:
- 一个在用户模式下执行的进程调用了系统调用,且相应的内核控制路径验证请求无法立即满足;它随后调用调度程序来选择一个新的进程执行。 结果,发生了进程切换。 第一个内核控制路径未完成,CPU恢复执行另一个内核控制路径。 在这种情况下,这两个控制路径是代表两个不同进程执行的。
- 当CPU在执行内核控制路径时,检测到一个异常,例如访问一个不在 RAM 中的页面。 第一个控制路径被挂起,CPU 开始执行一个合适的过程。 在我们的例子中,这个过程可能会为进程分配一个新页面,并从磁盘读取其内容。 当这个过程结束时,第一个控制路径可以恢复执行。 在这种情况下,这两个控制路径是代表同一个进程执行的。
- 当硬件中断发生时,且 CPU 在启用中断的情况下执行内核控制路径,第一个内核控制路径被挂起,CPU 开始执行另一个内核控制路径来处理该中断。 当中断处理程序终止时,第一个内核控制路径恢复执行。 在这种情况下,这两个内核控制路径是在同一个进程的执行上下文中运行的,并且所有的 CPU 时间都归该进程所有。 然而,中断处理程序不一定代表该进程进行操作。
- 当 CPU 在启用了内核抢占的情况下执行内核控制路径,并且有一个更高优先级的进程可以执行时,第一个内核控制路径未完成,CPU 恢复执行另一个代表更高优先级进程的内核控制路径。 只有当内核编译时启用了内核抢占支持时,才会发生这种情况。
进程地址空间
每个进程都在其私有地址空间中运行。 一个在用户模式下运行的进程会引用 私有栈、数据和代码区域。 当在内核模式下运行时,进程会访问内核的数据和代码区域,并使用另一个私有栈。
由于内核是可重入的,多个内核控制路径(每个与不同的进程相关)可能会依次执行。 在这种情况下,每个内核控制路径引用其自己的私有内核栈。
虽然每个进程看似都有访问私有地址空间的权限,但有时地址空间的某些部分是由多个进程共享的。 在某些情况下,这种共享是由进程显式请求的;在其他情况下,内核会自动进行共享,以减少内存使用。
如果同一个程序,例如一个编辑器,需要多个用户同时使用,该程序只会加载到内存一次,其指令可以由所有需要它的用户共享。 当然,它的数据不能共享,因为每个用户将有各自的数据。 这种共享地址空间是由内核自动完成的,以节省内存。
进程还可以共享它们地址空间的某些部分,作为一种进程间通信的方式,System V 引入了 “共享内存”技术,并且 Linux 支持该技术。
最后,Linux 支持 mmap() 系统调用,该调用允许将文件的某一部分或块设备上存储的信息映射到进程地址空间的某一部分。
内存映射可以作为数据传输的替代方式,替代常规的读写操作。
如果多个进程共享同一个文件,则该文件的内存映射会被包含在每个共享该文件的进程的地址空间中。
同步与临界区
实现可重入内核需要使用同步机制。 如果一个内核控制路径在操作内核数据结构时被挂起,则不应允许其他内核控制路径操作同一数据结构,除非该数据结构已被重置为一致的状态。 否则,两个控制路径的交互可能会破坏存储的信息。
例如,假设一个全局变量 V 表示某个系统资源的可用项数。 第一个内核控制路径 A 读取该变量并确定只有一个可用项。 此时,另一个内核控制路径 B 被激活,读取相同的变量,发现它仍然是1。 于是,B减少 V 的值并开始使用该资源项。 随后 A 恢复执行;由于它已经读取了 V 的值,它认为可以减少 V 并获取该资源项,而该资源项已经被 B 使用。 最终,V 的值变为 -1,并且两个内核控制路径试图使用同一个资源项,这可能导致灾难性的后果。
当一个计算的结果依赖于两个或多个进程的调度顺序时,代码是错误的。 这种情况被称为竞争条件(race condition)。
通常,通过使用原子操作来确保对全局变量的安全访问。 在前面的例子中,如果两个控制路径通过单个、不可中断的操作读取并减少 V 的值,则不会发生数据损坏。 然而,内核包含许多无法通过单一操作访问的数据结构。 例如,通常不能通过单个操作从链表中移除一个元素,因为内核需要同时访问至少两个指针。 任何必须由每个开始执行它的进程完成的代码段,在另一个进程进入之前,都被称为临界区(critical region)。
这些问题不仅发生在内核控制路径之间,还发生在共享公共数据的进程之间。 为了解决这些问题,已经采用了几种同步技术。以下部分将重点讨论如何同步内核控制路径。
禁用内核抢占
为了提供一种极为简单的同步问题解决方案,一些传统的Unix内核是非抢占式的:当一个进程在内核模式下执行时,它不能被任意挂起并被另一个进程替代。 因此,在单处理器系统上,所有未被中断或异常处理程序更新的内核数据结构对内核来说都是安全的。
当然,内核模式中的进程可以自愿放弃CPU,但在这种情况下,它必须确保所有数据结构保持一致的状态。 此外,当进程恢复执行时,它必须重新检查任何之前访问过的数据结构的值,因为这些值可能已经发生变化。
适用于抢占式内核的同步机制包括在进入临界区之前禁用内核抢占,并在离开临界区后立即重新启用它。
对于多处理器系统,仅仅禁用抢占是不够的,因为在不同 CPU 上运行的两个内核控制路径可以同时访问相同的数据结构。
禁用中断
另一种适用于单处理器系统的同步机制是在进入临界区之前禁用所有硬件中断,并在离开临界区后立即重新启用中断。 虽然这个机制简单,但远非最优。如果临界区较大,中断可能会长时间被禁用,从而可能导致所有硬件活动冻结。
此外,在多处理器系统中,禁用本地 CPU 的中断并不足够,必须使用其他同步技术。
信号量 (Semaphores)
一种广泛使用的机制,适用于单处理器和多处理器系统,依赖于信号量的使用。 信号量实际上是一个与数据结构关联的计数器;所有内核线程在尝试访问数据结构之前都会检查该信号量。 每个信号量可以视为一个由以下组成的对象:
- 一个整数变量
- 一个等待进程的列表
- 两个原子方法:
down()和up()
down() 方法减少信号量的值。
如果新的值小于 0,方法会将正在运行的进程加入信号量列表,然后将其阻塞(即调用调度程序)。
up() 方法增加信号量的值,如果新值大于或等于0,则重新激活信号量列表中的一个或多个进程。
每个要保护的数据结构都有一个自己的信号量,初始值为 1。
当一个内核控制路径希望访问数据结构时,它会在适当的信号量上执行 down() 方法。
如果信号量的新值不为负数,则允许访问数据结构。
否则,执行内核控制路径的进程会被加入信号量列表并被阻塞。
当另一个进程在该信号量上执行 up() 方法时,信号量列表中的一个进程将被允许继续执行。
自旋锁 (Spin locks)
在多处理器系统中,信号量并不总是同步问题的最佳解决方案。 有些内核数据结构应该防止被运行在不同 CPU 上的内核控制路径同时访问。 在这种情况下,如果更新数据结构所需的时间较短,使用信号量可能会非常低效。 为了检查信号量,内核必须将一个进程插入到信号量列表中,然后将其挂起。 由于这两个操作都相对昂贵,在完成这些操作所需的时间里,另一个内核控制路径可能已经释放了信号量。
在这些情况下,多处理器操作系统使用自旋锁。 自旋锁与信号量非常相似,但它没有进程列表;当一个进程发现锁被另一个进程关闭时,它会“自旋”,即反复执行紧凑的指令循环,直到锁变为开放。
当然,自旋锁在单处理器环境中是无用的。 当一个内核控制路径尝试访问被锁定的数据结构时,它会陷入一个无休止的循环。 因此,正在更新受保护数据结构的内核控制路径将无法继续执行并释放自旋锁。 最终结果将是系统挂起。
避免死锁
进程或内核控制路径在与其他控制路径同步时,可能很容易进入死锁状态。 死锁的最简单情况发生在进程 p1 获得数据结构 a 的访问权限,进程 p2 获得 b 的访问权限,但 p1 随后等待 b,p2 等待 a。 其他更复杂的进程组之间的循环等待也可能发生。 当然,死锁条件会导致受影响的进程或内核控制路径完全冻结。
就内核设计而言,当使用的内核锁数量较多时,死锁就成为一个问题。 在这种情况下,确保所有可能的内核控制路径交替执行方式中都不会发生死锁状态可能非常困难。 包括 Linux 在内的几个操作系统通过按照预定义的顺序请求锁来避免这个问题。
信号与进程间通信
Unix 信号提供了一种通知进程系统事件的机制。
每个事件都有其对应的信号编号,通常通过符号常量(如 SIGTERM)来表示。
系统事件有两种类型:
- 异步通知
例如,用户可以通过在终端按下中断键(通常是Ctrl-C)来向前台进程发送中断信号
SIGINT。 - 同步通知
例如,当进程访问一个无效地址的内存位置时,内核会向该进程发送信号
SIGSEGV。
POSIX标准定义了大约 20 种不同的信号,其中 2 种是用户可定义的,可以作为用户模式下进程之间通信和同步的基本机制。 一般来说,进程可以以两种方式响应信号的传递:
- 忽略信号。
- 异步执行指定的程序(信号处理程序)。
如果进程没有指定其中一种方式,内核会执行一个默认动作,这个动作取决于信号编号。 五种可能的默认动作是:
- 终止进程。
- 将执行上下文和地址空间的内容写入文件(核心转储),并终止进程。
- 忽略信号。
- 挂起进程。
- 如果进程是停止状态,恢复进程的执行,。
内核信号处理相当复杂,因为 POSIX 语义允许进程暂时阻塞信号。
此外,SIGKILL 和 SIGSTOP 信号不能由进程直接处理或忽略。
AT&T 的 Unix System V 引入了其他类型的进程间通信机制,这些机制已被许多 Unix 内核采纳:信号量、消息队列和共享内存。 它们统称为 System V IPC。
内核将这些结构实现为 IPC 资源。
进程通过调用 shmget()、semget() 或 msgget() 系统调用来获取一个资源。
像文件一样,IPC 资源是持久的:它们必须由创建进程、当前拥有者或超级用户进程显式地释放。
消息队列允许进程通过使用 msgsnd() 和 msgrcv() 系统调用交换消息,分别向特定的消息队列中插入消息和从消息队列中提取消息。
POSIX标准(IEEE Std 1003.1-2001)定义了一种基于消息队列的 IPC 机制,通常称为 POSIX 消息队列。 它们与 System V IPC 的消息队列类似,但提供了一个更简化的基于文件的接口给应用程序。
共享内存提供了进程交换和共享数据的最快方式。
进程首先通过发出 shmget() 系统调用来创建一个具有所需大小的新共享内存。
在获得 IPC 资源标识符后,进程调用 shmat() 系统调用,返回该新区域在进程地址空间中的起始地址。
当进程希望从其地址空间中分离共享内存时,调用 shmdt() 系统调用。
共享内存的实现依赖于内核如何实现进程地址空间。
进程管理
Unix 在进程和其执行的程序之间做了明确的区分。
为此,fork() 和 _exit() 系统调用分别用于创建新进程和终止进程,而类似 exec() 的系统调用用于加载新程序。
执行此类系统调用后,进程将在一个全新的地址空间中继续执行,该地址空间包含加载的程序。
调用 fork() 的进程是父进程,而新创建的进程是子进程。
父进程和子进程可以相互找到对方,因为描述每个进程的数据结构包括指向其直接父进程的指针以及指向所有直接子进程的指针。
fork() 的朴素实现会要求复制父进程的数据和代码,并将这些副本分配给子进程,这将非常耗时。
当前的内核可以依赖硬件分页单元,通常采用写时复制(Copy-On-Write,COW)的方法,推迟页面复制,直到最后一刻(即,直到父进程或子进程需要写入某个页面时)。
_exit() 系统调用终止一个进程。
内核通过释放进程拥有的资源并向父进程发送一个 SIGCHLD 信号来处理这个系统调用,默认情况下该信号会被忽略。
僵尸进程
父进程如何查询其子进程的终止情况?
wait4() 系统调用允许进程等待直到其子进程终止;它返回已终止子进程的进程 ID(PID)。
在执行此系统调用时,内核会检查子进程是否已经终止。
引入了一种特殊的僵尸进程状态来表示已终止的进程:进程会保持这种状态,直到其父进程对其执行 wait4() 系统调用。
系统调用处理程序从进程描述符字段中提取资源使用信息;数据收集完成后,可以释放进程描述符。
如果在执行 wait4() 系统调用时没有子进程已经终止,内核通常会将该进程置于等待状态,直到有子进程终止。
许多内核还实现了 waitpid() 系统调用,它允许进程等待特定的子进程。
wait4() 系统调用的其他变体也非常常见。
内核将子进程的信息保留到父进程发出 wait4() 调用是一个好做法,但如果父进程在未发出该调用的情况下终止呢?
此时,相关信息会占用宝贵的内存空间,这些内存本可以用于服务正在运行的进程。
例如,许多 Shell 允许用户在后台启动一个命令,然后退出登录。
运行命令的 Shell 进程终止,但其子进程继续执行。
解决方案是使用一个特殊的系统进程,称为 init,它在系统初始化时创建。
当一个进程终止时,内核会改变所有已终止进程的子进程描述符指针,使它们成为 init 进程的子进程。
init 进程监控所有子进程的执行,并定期发出 wait4() 系统调用,其作用是清理所有孤立的僵尸进程。
进程组和登录会话
现代 Unix 操作系统引入了进程组的概念,用来表示“作业”(job)。 例如,为了执行以下命令行:
$ ls | sort | more
一个支持进程组的 Shell,如 bash,会为 ls、sort 和 more 三个进程创建一个新的进程组。
这样,Shell 就可以将这三个进程视为一个单一实体(即作业)。
每个进程描述符都包含一个字段,存储进程组 ID。
每个进程组可能有一个组长进程,组长进程的 PID 与进程组ID 相同。
新创建的进程最初会被插入到其父进程的进程组中。
现代 Unix 内核还引入了登录会话。
非正式地说,一个登录会话包含了所有作为特定终端上工作会话后代的进程,通常是为用户创建的第一个命令 Shell 进程。
一个进程组中的所有进程必须处于同一个登录会话中。
一个登录会话可以同时有多个进程组处于活动状态;其中一个进程组总是在前台,即它能够访问终端。
其他活动的进程组则处于后台。
当后台进程尝试访问终端时,它会收到一个 SIGTTIN 或 SIGTTOUT 信号。
在许多命令 Shell 中,内部命令 bg 和 fg 可以用来将进程组放到后台或前台。
内存管理
内存管理是 Unix 内核中最复杂的活动之一。本节展示了与内存管理相关的一些主要问题。
虚拟内存
所有现代 Unix 系统都提供了一种有用的抽象——虚拟内存。 虚拟内存充当应用程序内存请求与硬件内存管理单元(MMU)之间的逻辑层。 虚拟内存有许多目的和优点:
- 多个进程可以并发执行。
- 可以运行需要比可用物理内存更大的内存的应用程序。
- 进程可以执行部分加载到内存中的程序代码。
- 每个进程只能访问一部分可用的物理内存。
- 进程可以共享库或程序的单一内存映像。
- 程序可以是可重定位的——即它们可以放置在物理内存的任何位置。
- 程序员可以编写与机器无关的代码,因为他们无需关心物理内存的组织方式。
虚拟内存子系统的核心概念是虚拟地址空间的概念。 一个进程可以使用的内存引用集与物理内存地址不同。 当进程使用虚拟地址时,内核和内存管理单元(MMU)合作,找到请求的内存项的实际物理位置。
如今的 CPU 包括自动将虚拟地址转换为物理地址的硬件电路。 为此,系统将可用的 RAM 划分为页面框架(通常是4KB或8KB大小),并引入了一组页表,指定虚拟地址如何对应到物理地址。 这些电路使内存分配变得更加简单,因为对一块连续虚拟地址的请求可以通过分配一组物理地址不连续的页面框架来满足。
使用随机存取内存(RAM)
所有 Unix 操作系统明确区分了随机存取内存(RAM)的两个部分。 一些内存专用于存储内核映像(即内核代码和内核静态数据结构)。 剩余的 RAM 通常由虚拟内存系统管理,并可用于以下三种方式:
- 满足内核对缓冲区、描述符和其他动态内核数据结构的请求
- 满足进程对通用内存区域以及文件内存映射的请求
- 通过缓存提高磁盘和其他缓冲设备的性能
每种请求类型都是重要的。 另一方面,由于可用 RAM 是有限的,因此在请求类型之间需要进行平衡,特别是在可用内存较少时。 此外,当可用内存达到某个临界阈值,并且启动页面框架回收算法以释放额外内存时,哪些页面框架最适合回收呢? 这个问题没有简单的答案,理论上也没有很好的支持。唯一的解决方案是开发经过精心调整的经验性算法。
虚拟内存系统必须解决的一个主要问题是内存碎片化。 理想情况下,只有当空闲页面框架的数量过少时,内存请求才应失败。 然而,内核经常被迫使用物理上连续的内存区域。 因此,即使有足够的内存可用,内存请求仍然可能失败,因为内存并不是以一个连续的块存在。
内核内存分配器
内核内存分配器(KMA)是一个子系统,它试图满足来自系统各个部分的内存请求。 这些请求中有一些来自其他需要内存的内核子系统,有一些则来自通过系统调用的用户程序,以扩展其进程的地址空间。 一个好的内核内存分配器应具备以下特点:
- 速度快。实际上,这是最关键的属性,因为它被所有内核子系统调用(包括中断处理程序)。
- 尽量减少浪费的内存。
- 尽力减少内存碎片化问题。
- 能够与其他内存管理子系统合作,从它们那里借用和释放页面框架。
几种已提出的内核内存分配器(KMA),它们基于不同的算法技术,包括:
- 资源映射分配器
- Power-of-two free lists
- McKusick-Karels 分配器
- 伙伴系统
- Mach 的 Zone 分配器
- Dynix 分配器
- Solaris 的 Slab 分配器
Linux 的内核内存分配器使用了在伙伴系统之上构建的 Slab 分配器。
进程虚拟地址空间处理
进程的地址空间包含了该进程被允许引用的所有虚拟内存地址。
内核通常将进程的虚拟地址空间存储为一组内存区域描述符。
例如,当一个进程通过类似 exec() 的系统调用启动某个程序时,内核会为该进程分配一个虚拟地址空间,其中包括以下内存区域:
- 程序的可执行代码
- 程序的已初始化数据
- 程序的未初始化数据
- 初始程序栈(即用户模式栈)
- 所需共享库的可执行代码和数据
- 堆(程序动态请求的内存)
所有现代的 Unix 操作系统都采用了一种叫做需求分页的内存分配策略。
在需求分页中,进程可以在没有任何页面加载到物理内存的情况下启动程序执行。
当进程访问一个未在物理内存中的页面时,MMU 会生成一个异常;异常处理程序会查找受影响的内存区域,分配一个空闲页面,并将其初始化为相应的数据。
同样地,当进程通过使用 malloc() 或 brk() 系统调用(malloc() 内部调用 brk())动态请求内存时,内核仅会更新进程堆内存区域的大小。
只有当进程通过访问其虚拟内存地址触发异常时,才会为该进程分配一个页。
虚拟地址空间还允许其他高效的策略,比如前面提到的 写时复制(Copy On Write,COW) 策略。 例如,当创建一个新进程时,内核仅将父进程的页面框架分配给子进程的地址空间,但将其标记为只读。 当父进程或子进程尝试修改页面内容时,就会触发异常。 异常处理程序会为受影响的进程分配一个新的页,并用原始页面的内容初始化它。
缓存
大部分可用的物理内存被用作硬盘和其他块设备的缓存。 这是因为硬盘非常慢:一次磁盘访问需要几毫秒的时间,这与 RAM 访问时间相比非常长。 因此,磁盘通常是系统性能的瓶颈。 作为一种通用规则,在最早的 Unix 系统中已经实现的一种策略是尽可能推迟写入磁盘。 因此,之前从磁盘读取并且不再被任何进程使用的数据仍然会保留在 RAM 中。
这一策略的基础在于,新的进程很可能需要访问以前由已不存在的进程从磁盘读取或写入的数据。 当一个进程请求访问磁盘时,内核首先检查所需的数据是否已经存在于缓存中。 每次缓存命中时,内核就能够在不访问磁盘的情况下服务进程请求。
sync() 系统调用通过将所有“脏”缓冲区(即所有内容与相应磁盘块不同的缓冲区)写入磁盘来强制进行磁盘同步。
为了避免数据丢失,所有操作系统都会定期将脏缓冲区写回磁盘。
设备驱动程序
内核通过设备驱动程序与 I/O 设备交互。 设备驱动程序是内核的一部分,包含控制一个或多个设备的数据结构和函数,如硬盘、键盘、鼠标、显示器、网络接口和连接到 SCSI 总线的设备。 每个驱动程序通过特定的接口与内核的其他部分(甚至与其他驱动程序)交互。 这种方法具有以下优点:
- 设备特定的代码可以被封装在一个特定的模块中。
- 厂商可以添加新设备,而不需要了解内核源代码;只需了解接口规范即可。
- 内核以统一的方式处理所有设备,并通过相同的接口访问它们。
- 可以将设备驱动程序编写为模块,能够在内核中动态加载,而无需重启系统。如果某个模块不再需要,也可以动态卸载,从而最小化存储在 RAM 中的内核镜像大小。
当用户程序希望操作硬件设备的时候, 它们通过常见的与文件相关的系统调用和通常位于 /dev 目录中的设备文件向内核发出请求。 实际上,设备文件是设备驱动程序接口的用户可见部分。 每个设备文件都对应一个特定的设备驱动程序,内核通过该驱动程序执行请求的硬件操作。
在 Unix 刚发布时,图形终端不常见且昂贵,因此 Unix 内核只直接处理字母数字终端。 当图形终端变得普及时,引入了像 X Window 系统这样的专用应用程序,这些应用程序作为标准进程运行,并直接访问图形接口的 I/O 端口和 RAM 显示区域。 最近的 Unix 内核,如 Linux 2.6,提供了显卡显存的抽象,并允许应用软件访问这些缓冲区,而不需要了解图形接口的 I/O 端口。